CliMA provides state-of-the-art data assimilation and machine learning tools that enable users to calibrate their models using large amounts of data. CliMA’s research scientists and engineers continually upgrade these tools and made several breakthroughs in the past months.
CliMA’s data assimilation and machine learning (DA/ML) team, led by Oliver Dunbar, improved the scalability of one of their machine learning emulators. Think of emulators as accelerated data-driven models, trained to replicate the evolution of a complex system (in our case, a climate model). Once trained, emulators can be run millions of times using few computational resources. These large samples are essential to ascertain the spread or uncertainty of climate model parameters that comes from calibrating a model with noisy climate statistics. In the past, we used Gaussian processes as emulators, which have notorious poor scaling to high-dimensional problems. We improved the scalability of the emulators with random feature models. This allows CliMA’s DA/ML tools to learn the uncertainty of many more parameters simultaneously, and with higher-dimensional data.
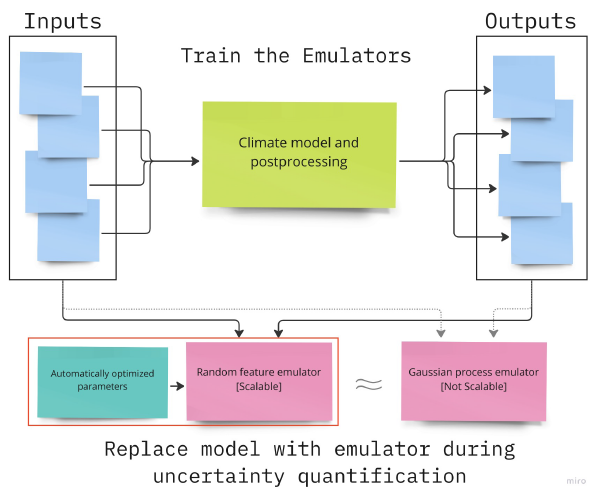
Commenting on how such a breakthrough was made, Dr. Dunbar, citing work from more than a decade ago, said that they have been aware of the inherent limitations of the currently-used Gaussian process emulators but had used them as necessary stepping stones. The surge came last quarter when Dr. Dunbar and graduate student Nicholas Nelsen developed new automated training procedures for emulators with random feature models, and have shown that they can be used to replace Gaussian process emulators within CliMA’s DA/ML tools. Interestingly, random feature emulators approximate Gaussian processes, but in a way that scales (with number of parameters and dimension of data) with reduced cost, while maintaining Gaussian processes’ desirable features (e.g., smoothing) for emulation of climate statistics. The random features emulator removes the key computational bottleneck in the CliMA DA/ML and uncertainty quantification pipeline.
Dr. Dunbar pointed out that no random feature package existed in the Julia registry—Julia is a computer language developed at MIT and used to develop the CliMA climate model–until CliMA’s DA/ML team registered their open-source Julia package: RandomFeatures.jl.
“We’ve created a novel, gradient-free training procedure” confirmed Dr. Dunbar, “We hope that this package and its automated training algorithm will promote both the use of random features, and the use of gradient-free training for machine learning tools to the community. We are documenting this work in a forthcoming article (Dunbar, Nelsen, Mutic, 2023).”
The work in the DA/ML team continues to progress at a remarkable pace: there have been advances in some of their other machine learning tools, such as using generative AI for downscaling climate simulations to impact-relevant local scales. And so, alongside their open approach to software development, scientists and engineers across a wide array of fields are certain to benefit from their efforts.