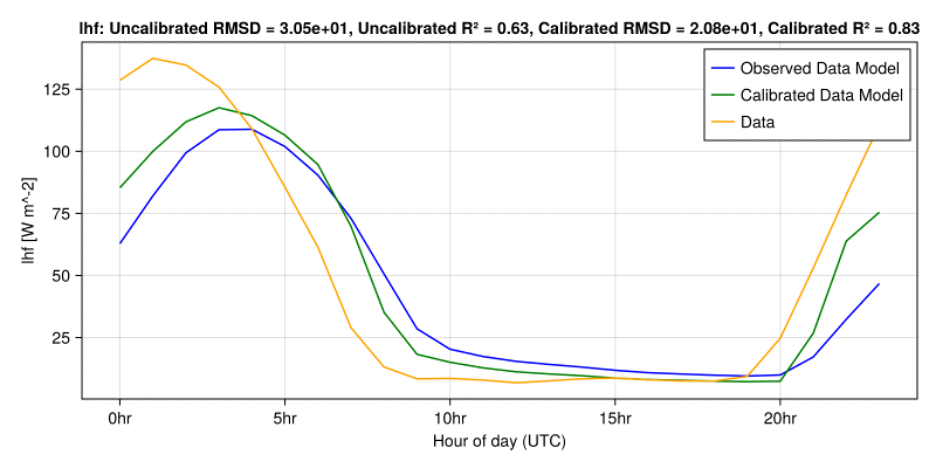
Over a 10-week summer period, the CliMA project welcomed three Summer Undergraduate Research Fellowship (SURF) interns. These undergraduate students were mentored by CliMA project scientists and software engineers on individual research projects that contributed to our model development. Thanhthanh Noel Nguyen, a second-year Caltech undergraduate, collaborated with Software Engineer Julia Sloan and the Land team. Her project focused on calibrating land models using FLUXNET observations, investigating how vegetation parameters vary with environmental conditions. Thanhthanh said “Julia was so patient and understanding to me, always ready to help … Everyone else at CliMA was also super friendly, and I always felt…
Read More
Recent posts
By Renato Braghiere Vegetation plays a critical role in regulating Earth’s climate by absorbing sunlight, exchanging moisture with the atmosphere, and sequestering carbon. Yet, how vegetation is represented in climate models has remained surprisingly static for decades. Most climate models use a simplified classification called plant functional types (PFTs) — broad categories like “tropical trees” or “grasses” — and assign homogeneous optical properties to each. Real leaves, however, are much more diverse than suggested by PFTs. Their ability to reflect and transmit light varies with chlorophyll content, leaf thickness, and water content — traits that change with seasons, stress, and…
Read More
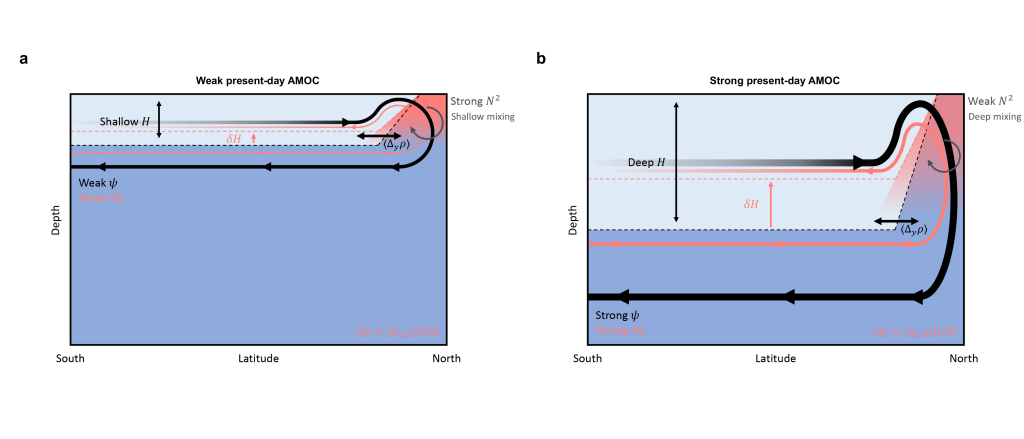
By Dave Bonan The ocean contains a system of currents that connects different ocean basins. A significant feature of this system is found in the Atlantic Ocean basin and often referred to as the Atlantic meridional overturning circulation (AMOC). The AMOC is crucial because it transports warm water northward and helps circulate water between the deep ocean and the surface. As a result, the AMOC plays a vital role in regulating both regional and global climates and can influence weather patterns, such as the African and Indian monsoons, and the summer climate in North America and Western Europe. The AMOC…
Read More

Numerical modeling is one of the pillars of ocean and climate science, and numerical simulations of ocean processes are critical for climate projections. Fortunately, recent rapid progress in computational tools — driven by AI — holds massive potential for accelerating numerical model development, and therefore progress in ocean and climate science. But this potential isn’t yet realized because traditional models can’t use AI hardware, don’t benefit from new programming tools and languages designed to accelerate AI model development, and can’t solve the full breadth of emerging ocean modeling problems. Enter Oceananigans — a popular, next-generation, GPU-accelerated ocean modeling framework developed…
Read More
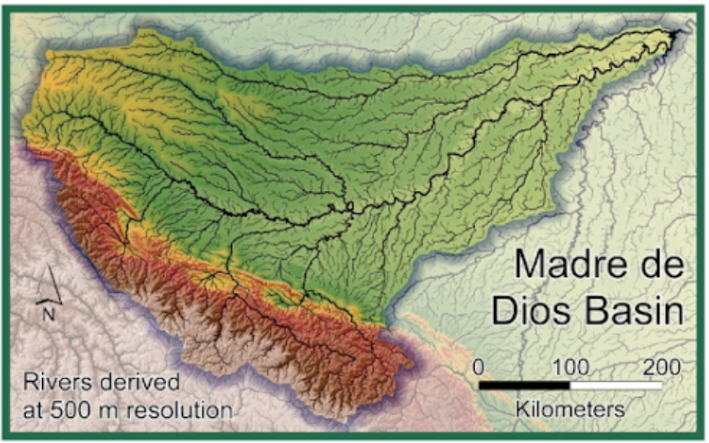
Land surface water routing describes how water flows on hillslopes and through river channels on the Earth’s surface. At a very high level, these processes close the water cycle on Earth and therefore are also required in climate models. Rivers provide freshwater to the ocean at river deltas, play a pivotal role in local wild environments, supply communities with water, and present flood risks during periods of high flow. Modeling river flow and other surface routing processes is an important task for any Earth system model. Many river models used in land surface models are rooted in the physical laws…
Read More

By Emily de Jong The Challenge of Microphysics Scales Clouds provide a crucial link between human action and climate reaction, yet models struggle to represent these harbingers of shade and precipitation and how they respond to warming or human-emitted aerosols. The source of this challenge lies in a separation of scales: the physics that determine how clouds form and precipitate operate at timescales of seconds and length scales of microns. For instance, cloud droplets grow initially through water condensation, and in some clouds they begin to collide with each other, coalescing to form larger and larger droplets that fall out…
Read More
By Julia Sloan. Earth System Models (ESMs) provide valuable insights into the behavior of our planet’s complex interconnected physical systems. CliMA is developing an ESM composed of multiple component models, including atmosphere, ocean, and land. Each of these component models can be run on their own, which is useful for studying each of these domains independently and facilitates testing, calibration, and validation during model development. To gain understanding of the entire global system and predict future climate change, we need to run all of the component models together, including the feedback between them. This is where the coupling component, ClimaCoupler.jl,…
Read More

By Simone Silvestri, Gregory Wagner, and Raffaele Ferrari, for the MIT CliMA group. Ocean eddies—the ocean equivalent of atmospheric cyclones and anticyclones—play a key role in the Earth’s climate system. However, they are not simulated by climate models due to their small scale, between 10 and 100 km, which is below the resolution of standard ocean models. To approximate the climate impact of the missing eddies, modelers employ parameterizations—empirical equations that estimate the collective effect of eddies given resolved model variables such as ocean current strength, temperature, and salinity. Yet, this approach is fraught with uncertainties. For example, a 2002…
Read More

Cloud microphysics refers to the complex processes that govern the formation, evolution, and interactions of particles within clouds. These processes significantly influence the Earth’s climate system by regulating precipitation patterns and cloud cover. Understanding the intricacies of cloud microphysics is therefore essential for accurate climate modeling. Yet, the precise modeling of these complex microphysical processes remains one of the most challenging aspects of climate research. Traditional cloud microphysics modeling within climate models, known as bulk methods, aims to simplify the physics governing the vast range of processes occurring within clouds. While these methods have enabled more efficient climate simulations, their…
Read More

by Alexandre A. Renchon, Katherine Deck, Renato Braghiere: In the realm of scientific advancement, enhancing Earth System Models (ESMs) stands out as a paramount objective. Presently, however, these models remain enigmatic enclaves for many researchers, akin to inscrutable black boxes. The labyrinthine nature of ESMs, coupled with their high computational demands, usage of esoteric programming languages, and the absence of lucid documentation and user interfaces, contribute to this opacity. To surmount these obstacles, CliMA is creating a new era of accessible ESM features for the global scientific community: Modernized Programming: Departing from convention, CliMA adopts a contemporary programming language, Julia.…
Read More